1.1 数据湖的定义及发展需求
数据湖(Data Lake)是Pentaho的CTO James Dixon提出来的,是一种数据存储理念——即在系统或存储库中以自然格式存储数据的方法。
目前,Hadoop是最常用的部署数据湖的技术,所以很多人会觉得数据湖就是Hadoop集群。数据湖是一个概念,而Hadoop是用于实现这个概念的技术。数据湖到底是什么?业内并没有达成共识定义。我们先看看Amazon AWS把数据湖定义为: Amazon S3存储、数据目录、数据冷备;并辅之以数据移动工具、数据分析工具、机器学习工具。注:为了维持定义的精确性, 看英文原文如何描述。从Amazon AWS得到的解释:
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.

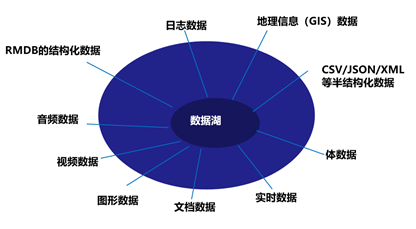
图1.数据湖存储数据类型
数据湖是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。数据湖从企业的多个数据源获取原始数据,并且针对不同的目的,同一份原始数据还可能有多种满足特定内部模型格式的数据副本。

图2.未经处理和包装的原生状态“水库”
(1)数据湖是有一个中心化的存储,所有的数据以它本来的形式【包括结构化数据(关系数据库数据),半结构化数据(CSV、XML、JSON等),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像、音频、视频)】从而形成一个容纳所有形式数据的集中式数据存储,进而为后续的报表、可视化分析、实时分析、以至于机器学习提供数据支撑。
(2)数据湖就像一个大型容器,与真正的湖泊和河流非常相似。就像在湖中你有多个支流进来一样,数据湖有结构化数据,非结构化数据,机器到机器,实时流动的日志。
(3)数据湖是一种经济有效的方式来存储组织的所有数据以供以后处理。研究分析师可以专注于在数据中找到意义模式而不是数据本身。
1.2 从数据库、数据仓库到数据湖演变趋势
从1960年开始,数据管理经历了数据收集、数据库、数据仓库的阶段,2001年后随着互联网的迅速发展,大数据时代来临,对数据管理技术提出了全新的要求,未来朝着数据湖的方向演进。

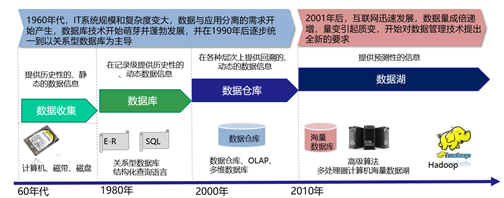
图3.数据库、数据仓库到数据湖发展历程
数据库的数据有对齐的要求,数据库是面向应用的,每个应用可能需要一个数据库。如果一个公司有几十个应用,就会有几十个数据库。几十个数据库之间怎么去连接分析、统一分析?是没有办法的。
随后就由数据库发展成了一个数据仓库,数据仓库不面向任何应用。但是,它对接到数据库,如果需要每天定时有些 ETL 的批处理的任务,将不同应用和数据汇总起来,按照一些范式模型去做连接分析,得到一定时间段的总体数据视图。这个前提是很多数据库要给数仓供应数据。
而随着数据量的增加及数据类型的变化,很多非结构化的数据,比如视频、音频及文档等占据数据总量的比例越来越多。原来的数据仓库已经很难继续支撑,因此越来越多的企业希望把原始数据以真实的初始状态保留下来。在这种需求的推动下,数据湖的理念便开始成形,其可以把数据保存在原始状态,以便于企业从多个维度进行更多分析。数据可以很轻松进入数据湖,用户也可以延迟数据的采集、数据清洗、规范化的处理,可以把这些延迟到业务需求来了之后再进行处理。传统的数仓,因为模型范式的要求,业务不能随便的变迁,变迁涉及到底层数据的各种变化。相对来说,数据湖就更加的灵活,能更快速的适应上层数据应用的变化。
1.3 数据仓库与数据湖差异
数据湖是按原始数据格式存储,旨在任何数据可以以最原始的形态储存,可是结构化或者非结构化数据,以确保数据在使用时可以不丢失任何细节,所有的实时数据和批量数据,都汇总到数据湖当中,然后从湖中取相关数据用于机器学习或者数据分析。
(1)相关差异点
- 在储存方面上,数据湖中所有数据都保持原始形式,仅在分析时再进行转换。数据仓库就是数据通常从业务系统中提取。
- 在将数据加载到数据仓库之前,会对数据进行清理与转换。在数据抓取中,数据湖就是捕获半结构化和非结构化数据。而数据仓库则是捕获结构化数据并将其按模型来组织。
- 数据湖的目的就是数据湖适合深入分析的非结构化数据。数据科学家可能会用具有预测建模和统计分析等功能的高级分析工具。而数据仓库就是数据仓库非常适用于数据指标、报表、报告等分析用途,因为它具有高度结构化。
- 数据湖通常在存储数据之后定义架构,较少的初始工作并提供更大的灵活性。而在数据仓库中存储数据之前需定义架构。

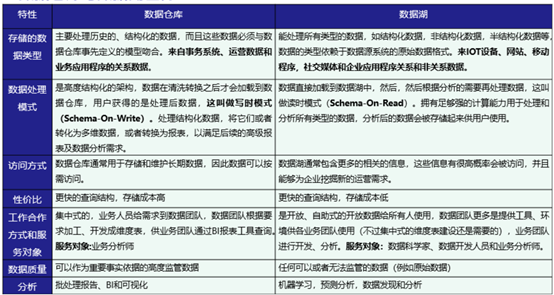
图4.数据仓库和数据湖的差异和联系
(2) 数据湖主要特点
- 数据湖与数据仓库的理念不同,相对于数据仓库的注重数据管控,数据湖更倾向于数据服务。
- 数据湖对数据从业人员的素质要求更高;对数据系统的要求更高,要防止数据湖变数据沼泽,此时就需要借助现代化的数据治理能力。
- 数据湖与数据仓库不是互斥的。当前条件下,数据湖并不能完全替代数据仓库。尤其是对于已经使用数据仓库的公司,这种情况下数据仓库可以作为数据湖的一个数据来源。
- 与数据存储在文件和文件夹中的分层数据仓库不同,数据湖具有扁平的架构。数据湖中的每个数据元素都被赋予唯一标识符,并标记有一组元数据信息。
- 数据湖的三个层次,分为数据库等底层存储、元数据管理、跨不同数据源的 SQL 引擎。数据湖也是数据仓库发展的高级阶段,对于数据仓库来说,数据湖有很多扩展能力。数据仓库解决的核心问题,数据湖也解决了一遍,而且涉及面更广。
1.4 数据湖架构体系
数据、算法和算力三大因素正在全力推动数据湖应用快速发展。企业建立统一的数据湖平台,完成数据的采集、存储、处理、治理,提供数据集成共享服务、高性能计算能力和大数据分析算法模型,支撑经营管理数据分析应用的全面开展。为规模化数据应用赋能。
笔者认为,数据湖技术架构涉及了数据接入(转移)、数据存储、数据计算、数据应用、数据治理、元数据、数据质量、数据资源目录、数据安全及数据审计等10个方面领域,以下简要作一介绍:

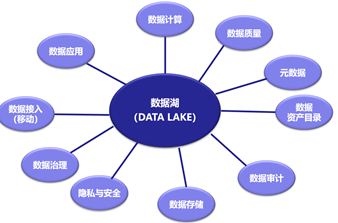
图5.数据湖包含技术体系
1)数据接入(移动)
数据提取允许连接器从不同的数据源获取数据并加载到数据湖中。数据提取支持:所有类型的结构化,半结构化和非结构化数据。批量,实时,一次性负载等多次摄取;在数据接入方面,需提供适配的多源异构数据资源接入方式,为企业数据湖的数据抽取汇聚提供通道。
2)数据存储
数据存储应是可扩展的,提供经济高效的存储并允许快速访问数据探索。它应该支持各种数据格式。
3)数据计算
数据湖需要提供多种数据分析引擎,来满足数据计算需求。需要满足批量、实时、流式等特定计算场景。此外,向下还需要提供海量数据的访问能力,可满足高并发读取需求,提高实时分析效率。并需要兼容各种开源的数据格式,直接访问以这些格式存储的数据。
4)数据治理
数据治理是管理数据湖中使用的数据的可用性,安全性和完整性的过程。数据治理是一项持续的工作,通过阐明战略、建立框架、制定方 针以及实现数据共享,为所有其他数据管理职能提供指导和监督。
5)元数据
元数据管理是数据湖整个数据生命周期中需要做的基础性工作,企业需要对元数据的生命周期进行管理。元数据管理本身并不是目的,它是组织从其数据中获得更多价值的一种手段,要达到数据驱动,组织必须先是由元数据驱动的。
6)数据资源目录
数据资源目录的初始构建,通常会扫描大量数据以收集元数据。目录的数据范围可能包括全部数据湖中被确定为有价值和可共享的数据资产。数据资源目录使用算法和机器学习自动完成查找和扫描数据集、提取元数据以支持数据集发现、暴露数据冲突、推断语义和业务术语、给数据打标签以支持搜索、以及标识隐私、安全性和敏感数据的合规性。
7)隐私与安全
数据安全是安全政策和安全程序的规划、开发和执行、以提供对数据和信息资产的身份验证、授权、访问和审核。需要在数据湖的每个层中实现安全性。它始于存储,发掘和消耗,基本需求是停止未授权用户的访问。身份验证、审计、授权和数据保护是数据湖安全的一些重要特性。
8)数据质量
数据质量是数据湖架构的重要组成部分。数据用于确定商业价值,从劣质数据中提取洞察力将导致质量差的洞察力。数据质量重点关注需求、检查、分析和提升的实现能力,对数据从计划、获取、存储、共享、维护、应用、消亡生命周期的每个阶段里可能引发的各类数据质量问题进行识别、度量、监控、预警等一系列活动,并通过改善和提高组织的管理水平使得数据质量获得进一步提高。
9) 数据审计
两个主要的数据审计任务是跟踪对关键数据集的更改:跟踪重要数据集元素的更改;捕获如何/何时/以及更改这些元素的人员。数据审计有助于评估风险和合规性。
10) 数据应用
数据应用是指通过对数据湖的数据进行统一的管理、加工和应用,对内支持业务运营、流程优化、营销推广、风险管理、渠道整合等活动,对外支持数据开放共享、数据服务等活动,从而提升数据在组织运营管理过程中的支撑辅助作用,同时实现数据价值的变现。在基本的计算能力之上,数据湖需提供批量报表、即席查询、交互式分析、数据仓库、机器学习等上层应用,还需要提供自助式数据探索能力。



